大数据时代到来,网络数据正成为潜在宝藏,大量商业信息、社会信息以文本等存储在网页中,这些具有相当大价值的信息不同于传统的结构化数据,属于非结构化数据,需要我们使用一定的技术和方法将其转化为计算机能够理解的特征信息,然后我们才能对其进行分析。这里我们采用python爬虫提取腾讯网站科技新闻的标题,通过文本分析,来进行分析。
数据获取数据获取来源是QQ门户网站科技区频道https://new.qq.com/ch/tech/瀑布流热点新闻的标题。
我们使用selenium工具进行数据获取,相对于常用的urllib、beautifulsoup和request爬虫模块,使用selenium能对WEB浏览器进行自动化操作,优点是获取的数据所见即所得,不用写和测试GET网页的配置,对瀑布流式的数据获取简单,缺点要等待浏览器对数据的加载,速度较慢。
与其他爬虫方法一样,我们需要通过HTML的标签来获取数据。
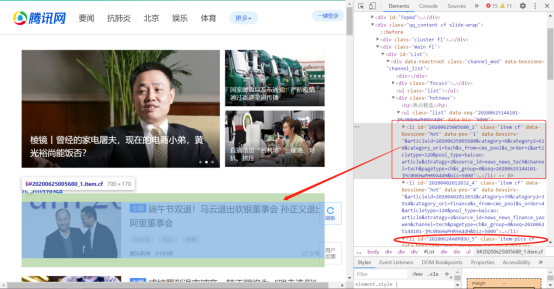
HTML元素分析1
可以看到,热点新闻的链接存放在<li>标签中,属性class=”item cf”或”item-pics”,且属性id是唯一标识,包含时间属性。
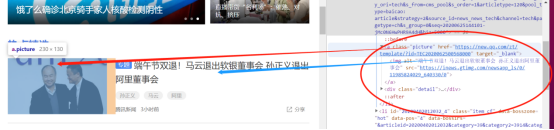
HTML元素分析2
展开标签<li>我们可以看到里面包含标签<a>,标题信息就在之中。因此我们获取数据的思路就有了。
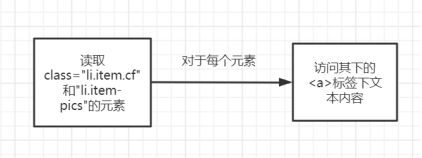
爬虫流程
代码语言:javascript
复制
# 从标签class获取元素 elements1 = browser.find_elements_by_css_selector('li.item.cf') elements2 = browser.find_elements_by_css_selector('li.item-pics') write_conn, read_conn = Pipe() process = Process(target=recv, args=(write_conn,)) process.start() for element in elements1: # 获取<a>的内容 a = element.find_element_by_tag_name('a') print(a.get_attribute("innerHTML")) if len(element.get_attribute('id')) > 0: read_conn.send((element.get_attribute('id'), a.get_attribute("innerHTML"))) else: read_conn.send(('20200624002985_1', a.get_attribute("innerHTML"))) for element in elements2: a = element.find_element_by_tag_name('a') if len(element.get_attribute('id')) > 0: read_conn.send((element.get_attribute('id'), a.text)) else: read_conn.send(('20200624002985_1', a.text))
腾讯新闻门户网站的新闻采取的是瀑布流式刷新,当用户鼠标滑动向下,才会有新数据加载到浏览器。所以我们还得让浏览器滑动滚轴,根据测试腾讯新闻每天会更新几百条新闻,若想全部加载完大概有2000多条,在我的运行机器上大概需要10分钟的滑动。我们还能配置浏览器关闭图片获取,加快速度。
代码语言:python
代码运行次数:0
复制
Cloud Studio 代码运行start = time.time() while time.time() - start < 1 * 12: # 随机的滑动距离 distance = random.randint(300, 400) js = 'window.scrollBy(0,' + str(distance) + ')' # 浏览器滑动 browser.execute_script(js) # 随机的休息时间 time.sleep(random.uniform(0.2, 0.4))
爬虫过程截图
通过测试我们发现,在滑动完毕后读取数据会出现之前查看不到的<div>标签,通过class名字我们知道这是一个慢加载的内容,原因是滑动后马上读取数据,但是仍有未收到的HTTP数据,浏览器无法加载完毕。解决的办法是可以在滑动后让程序sleep一段时间再读取元素。
爬完后接下来我们利用正则表达式将不同标签下的标题提出出来:
代码语言:javascript
复制
r = re.findall(r'\"([^\"]*)\"', t) #提取<img alt... r = re.findall(r'<div class=".*">(.*?)</div>', t) #提取<div class...

抓取部分截图
文本分析将爬取到的所有标题写入txt文件中形成我们的目标分析文本。利用TextRank算法来进行文本分析。TextRank算法可以用来提取关键词和摘要。TextRank4ZH是指针对中文文本的TextRank算法的python算法实现。
TextRank算法思路:
把给定的文本 T 按照完整句子进行分割,即:T=[S1,S2,…,Sm]
对于每个句子,进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词,其中 ti,j 是保留后的候选关键词。Si=[ti,1,ti,2,...,ti,n]
构建候选关键词图 G = (V,E),其中 V 为节点集,由(2)生成的候选关键词组成,然后采用共现关系(Co-Occurrence)构造任两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为K 的窗口中共现,K表示窗口大小,即最多共现 K 个单词。
根据 TextRank 的公式,迭代传播各节点的权重,直至收敛。
对节点权重进行倒序排序,从而得到最重要的 T 个单词,作为候选关键词。
由 5 得到最重要的 T 个单词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词。
TextRank4ZH是针对中文文本的TextRank算法的python算法实现。在命令行中安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple
代码语言:javascript
复制
import sys import Lib try: Lib.reload(sys) sys.setdefaultencoding('utf-8') except: pass import codecs from textrank4zh import TextRank4Keyword text = codecs.open('./doc/腾讯1天.txt', 'r', 'utf-8').read() tr4w = TextRank4Keyword() tr4w.analyze(text=text,lower=True, window=3, pagerank_config={'alpha':0.85}) word_list='' phrase_list='' keywd=[] keywg=[] for item in tr4w.get_keywords(30, word_min_len=2): word_list=word_list+' '+item.word keywd.append(item.word) keywg.append(item.weight) #print('--phrase--') for phrase in tr4w.get_keyphrases(keywords_num=30, min_occur_num = 0): phrase_list = phrase_list + ' ' + phrase
将频率出现次数最高的前30个关键词提取出来以条状图进行展现:
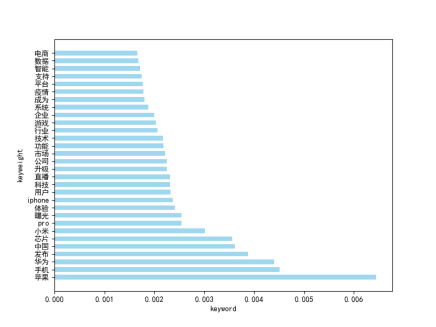
高频词可视化数据
可以看出手机领域是近期常出现的新闻,在年中,很多手机厂商发布了新款旗舰手机,所以热点颇多。其中广受关注的就是Apple、华为和小米公司。
选取出现次数大于5次和10次的短语:

出现次数大于5次的短语

出现次数大于10次的短语
可以看出直播带货是近期讨论较为频繁的话题,苹果发布会的话题是爆发较大的话题
词云将提取到的关键词或关键词组拼接成字符串利用WordCloud包生成词云,将高频率的关键词或关键词组进行视觉上的突出。
在python中生成词云时,出现导入Wordcloud包失败,wordcloud是python第三方词云库,需要下载wordcloud编译后安装包,将文件放入python.exe存在的位置;
执行pip install wordcloud-1.5.0-cp36-cp36m-win_amd64.whl ;
再重新执行pip install WordCloud,即安装成功。
高频词词云:

高频词词云
高频短语词云:

高频短语词云
通过条状图和词云图,我们可以直观地看到最近大家关注的科技新闻的热点。以我们分析的数据为例,当天的热点话题包括各苹果、华为、疫情、直播、芯片、手机等,由此我们可以直接定位热点的关键内容;通过关键词组的词云分析,我们可以扩展热点信息,如苹果芯片、功能体验、企业技术、升级一体验等,由此获取关键内容之间的联系。其中,苹果公司的动态位居话题首榜,这是因为苹果公司知名度广,其产品也是全球关注的明星产品,由于马太效应,其发布的产品动态也一直是民众、企业关注的重点。而通过条状图,我们可以看到苹果的话题的讨论热度明显高于其他关键词,因此我们也可以看出此次苹果芯片的发布动态的影响性之大,话题讨论热度之高。
我们通过爬取门户网站上的科技新闻标题并进行文本分析,最终通过可视化可以便于我们快速获得科技最热话题,可以使我们快速通过搜索高频率关键词或关键短语来获取最近的热点文章内容;而我们在进行科技话题分析时,各个相邻分布的高频率关键词或许也存在某种相关性,如苹果之后是手机、华为、中国等,给我们在进行话题分析时提供一种思路。
小结通过实践操作爬虫加文本分析来进行信息的分析,我们得出了有意思的结果。在实践过程中,我们遇到了很多问题,通过查找学习资料再一步步地解决了问题,由此收获了很多,发现也只有动手实践操,让知识落地才能真正地学会知识。而这次课题实验,我们也小小地领会到了爬虫和文本分析的作用,运用不同的文本分析的算法,或许我们还能得到更多其他的信息,而在今后的学习工作中,我们就可以利用python爬虫加文本分析来来研究其他方面的信息,来帮我们或许更多内容,解决一些关键性知识问题。



