【多GPU炼丹-绝对有用】PyTorch多GPU并行训练:深度解析与实战代码指南
2024-03-28 929
版权
版权声明:
本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《 阿里云开发者社区用户服务协议》和 《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写 侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
本文涉及的产品
全局流量管理 GTM,标准版 1个月
云解析DNS,个人版 1个月
云解析 DNS,旗舰版 1个月
简介: 本文介绍了PyTorch中利用多GPU进行深度学习的三种策略:数据并行、模型并行和两者结合。通过`DataParallel`实现数据拆分、模型不拆分,将数据批次在不同GPU上处理;数据不拆分、模型拆分则将模型组件分配到不同GPU,适用于复杂模型;数据和模型都拆分,适合大型模型,使用`DistributedDataParallel`结合`torch.distributed`进行分布式训练。代码示例展示了如何在实践中应用这些策略。
a. 数据拆分,模型不拆分 b. 数据不拆分,模型拆分 c. 数据拆分,模型拆分
在深度学习的炼丹之路上,多GPU的使用如同助燃剂,能够极大地加速模型的训练和测试。根据不同的GPU数量和内存配置,我们可以选择多种策略来充分利用这些资源。今天,我们将围绕“多GPU炼丹”这一主题,深度解析PyTorch多GPU并行训练的技巧,并为大家带来实战代码指南。在这个过程中,我们将不断探讨和展示如何利用PyTorch的强大功能,实现多GPU的高效并行训练。
首先,我们需要了解PyTorch是如何支持多GPU训练的。在PyTorch中,有多种方式可以实现多GPU的并行计算,包括DataParallel、DistributedDataParallel以及手动模型拆分等。每种方式都有其适用的场景和优缺点,我们需要根据具体的任务和数据集来选择合适的策略。主要分为数据并行和模型并行二种策略。
在这种策略中,我们将数据拆分成多个批次,每个批次在一个GPU上进行处理。模型不会拆分,而是复制到每个GPU上。
python import torch import torch.nn as nn 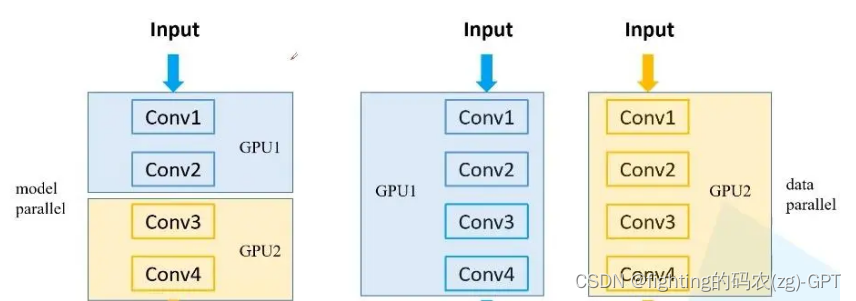 import torch.optim as optim from torch.utils.data import DataLoader, Dataset from torch.nn.parallel import DataParallel #### 假设我们有一个自定义的数据集和模型 class MyDataset(Dataset): # 实现__len__和__getitem__方法 pass class MyModel(nn.Module): # 定义模型结构 pass #### 初始化数据集和模型 dataset = MyDataset() dataloader = DataLoader(dataset, batch_size=32, shuffle=True, num_workers=4) model = MyModel() #### 检查GPU数量 device_ids = list(range(torch.cuda.device_count())) model = DataParallel(model, device_ids=device_ids).to(device_ids[0]) #### 定义损失函数和优化器 criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) #### 训练循环 for epoch in range(num_epochs): for inputs, labels in dataloader: inputs, labels = inputs.to(device_ids[0]), labels.to(device_ids[0]) optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() b. 数据不拆分,模型拆分在这种策略中,整个数据集在每个GPU上都会有一份副本,但模型会被拆分成多个部分,每个部分在一个GPU上运行。这种策略通常不常见,因为数据复制会消耗大量内存,而且模型拆分也可能会导致通信开销增加。不过,这里还是提供一个简化的示例:
python
注意:这个示例可能不适用于所有模型,因为模型拆分通常涉及到复杂的并行和通信策略。 这里只是为了演示目的。 #### 假设我们有一个可以拆分的模型(例如,具有多个子网络的模型) class SplitModel(nn.Module): def __init__(self): super(SplitModel, self).__init__() self.subnet1 = nn.Sequential(...) # 定义子网络1 self.subnet2 = nn.Sequential(...) # 定义子网络2 # ... 其他子网络 ... def forward(self, x): # 前向传播逻辑,可能涉及跨多个设备的通信和数据传输 pass #### 初始化模型和数据集(这里不实际拆分数据) model = SplitModel() dataset = MyDataset() #### 将模型的每个子网络分配到一个GPU上 model.subnet1 = model.subnet1.to('cuda:0') model.subnet2 = model.subnet2.to('cuda:1') #### ... 其他子网络 ... #### 训练循环(这里省略了数据加载和批处理,因为数据没有拆分) for epoch in range(num_epochs): inputs, labels = ... # 加载数据 inputs = inputs.to('cuda:0') # 假设输入数据首先被送到第一个GPU上 optimizer.zero_grad() outputs = model(inputs) # 前向传播可能涉及跨多个GPU的通信 loss = criterion(outputs, labels) loss.backward() optimizer.step() c. 数据拆分,模型拆分在这种策略中,我们同时使用数据并行和模型并行。数据被拆分成多个批次,每个批次在不同的GPU上进行处理,同时模型也被拆分成多个部分,每个部分在不同的GPU上运行。这通常用于非常大的模型,单个GPU无法容纳整个模型的情况。
以下是使用PyTorch的torch.distributed模块进行分布式训练的高层次概述和代码片段: python import torch import torch.distributed as dist import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, Dataset, DistributedSampler from torch.nn.parallel import DistributedDataParallel as DDP #### 自定义数据集和模型 class MyDataset(Dataset): # 实现__len__和__getitem__方法 pass class MyModel(nn.Module): # 定义模型结构,可能需要考虑如何拆分模型 pass #### 初始化分布式环境 dist.init_process_group(backend='nccl', init_method='tcp://localhost:23456', rank=0, world_size=torch.cuda.device_count()) #### 初始化数据集和模型 dataset = MyDataset() sampler = DistributedSampler(dataset) dataloader = DataLoader(dataset, batch_size=32, shuffle=False, sampler=sampler) model = MyModel() #### 拆分模型(这通常需要根据模型的具体结构来手动完成) #### 例如,如果模型有两个主要部分,可以将它们分别放到不同的设备上 model_part1 = model.part1.to('cuda:0') model_part2 = model.part2.to('cuda:1') #### 使用DistributedDataParallel包装模型 model = DDP(model, device_ids=[torch.cuda.current_device()]) #### 定义损失函数和优化器 criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) #### 训练循环 for epoch in range(num_epochs): for inputs, labels in dataloader: inputs, labels = inputs.to(model.device), labels.to(model.device) optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() #### 销毁分布式进程组 dist.destroy_process_group()请注意,上面的代码只是一个非常基础的示例,用于说明如何使用torch.distributed进行分布式训练。在实际应用中,您可能需要根据您的模型和数据集进行更复杂的模型拆分和数据加载。此外,您还需要处理多进程启动、错误处理和日志记录等问题。
在实际应用中,您可能需要参考PyTorch的官方文档和示例代码,以了解如何使用torch.distributed进行分布式训练。此外,还有一些高级库,如PyTorch Lightning,可以简化分布式训练的设置和管理。
具体GPT5教程参考:个人主页的个人简介内容:





