ChatGPT推出将近半年,大型语言模型已被视为科技巨头的标配。哪家没有,哪家就会感受到来自市场的异样眼光,似乎已经没有了未来。甚至连苹果,也已经开始被这样的眼光打量。
美国的大模型竞争,分为了两派。离商业化更近的微软与谷歌,它们走向封闭。本周,谷歌闭关了一阵之后,终于推出了PaLM 2,对自微软与OpenAI发起了反击。尽管ChatGPT的流量仅为自身的2%,但谷歌担心继续开放,会让竞争对手学了去。
离商业化稍远的Meta,继续开源之路。多模态的ImageBind包括温度、深度与运动等数据,甚至还将纳入触觉与气味等信息。有人将其视为元宇宙大模型,还有人联想到了杨立昆的世界模型。还有一众LLaMA的后代,也是托了Meta的福。
人们始终担心,现在的大模型开源热潮是不稳定的。大多数的开源版本,仍然站在财力雄厚的大公司推出的巨型模型的肩膀上。如果Meta也找到了最合适的商业化切入点,是否也会走向封闭?
对于一些人来说,开源是一个原则问题。对于其他人来说,这是一个利益问题。人们担心过度封闭会影响底层创新。目前,美国的很多大模型创新,来自规模更小的初创企业。
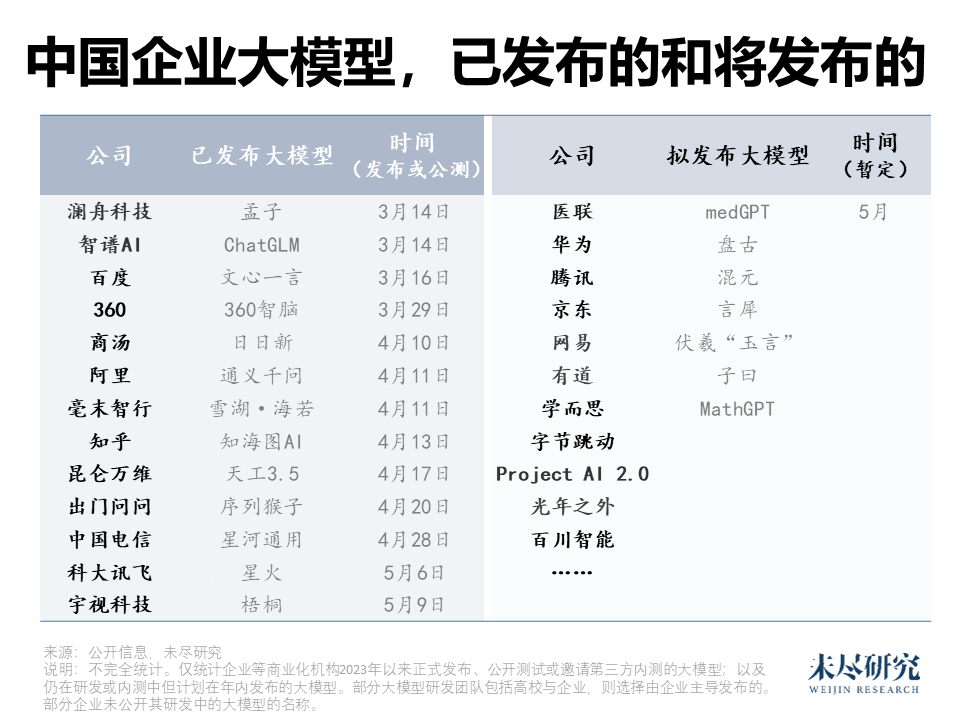
中国的幸福“烦恼”也许是市场太大,即使在其他国家是利基市场,在中国也足够企业施展商业的拳脚。资金也迫切看到经济回报。不完全统计,仅今年以来,中国企业正式发布或对外测试的大型语言模型约15家,算上计划发布的,已经接近30家。
它们几乎都是有着相对明确的应用场景,设想了变现路径,也就基本与开源无缘。有些瞄准教育,有些瞄准医疗,有些瞄准自动驾驶。百度与阿里面向的行业更广泛,它们有实力成为其他应用大模型的“底座”。但真正面向大量用户开放测试的,也只有百度一家。
腾讯与字节跳动也有机会。它们都有国民级应用,拥有大量数据与应用场景;它们都涉足短视频,尤其是字节跳动,视频生成正是本轮生成式人工智能相对缺乏亮点的细分领域。
与百度或阿里相比,它们的云服务相对较弱。但腾讯上个月刚发布了面向大模型训练的新一代HCC高性能计算集群,整体性能比过去提升了3倍。火山引擎的DPU+CPU+GPU混合算力结构,也与字节跳动国内业务大规模并池,实现大规模内外实时复用算力资源。它们将是今年下半年的重磅玩家。
以下是本周发生的足够有分量的几起AI大事件:
周一
ChatGPT流量增长趋缓
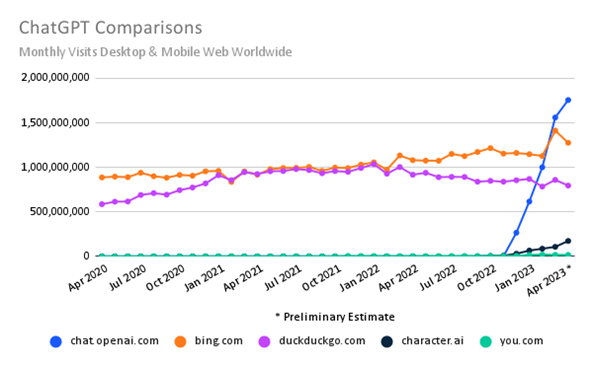
4月,ChatGPT全球访问量达到了 17.6 亿次,约为中国搜索引擎百度的60%,俄罗斯搜索引擎Yandex的75%,但仍仅为谷歌的2%。涌入ChatGPT的流量正在趋缓,4月环比增长12.6%,某种程度上是因为它成为了其他网站的“Intel Inside”服务。此外,越来越多公司担心泄露隐私数据而禁止员工就工作任务访问ChatGPT。
ChatGPT月访问量对比(全球,PC+移动)
今年前四月,ChatGPT流量环比增速分别为131.6%、62.5%、55.8%与12.6%。来源SimilarWeb
周二
Meta 开源多感官模型,世界模型雏形?
Meta公布了新的开源人工智能模型ImageBind,把不同模态数据串联在一个嵌入空间(Embedding Space),让其从多维度理解世界。目前的数据包括文本、音频、视觉、温度、深度和运动等,未来或许还会有触觉、气味和大脑fMRI信号等。ImageBind目前只是研究项目,但已有人将其与元宇宙、机器人和世界模型联系了起来。
OpenAI用GPT-4解释GPT-2
OpenAI发表了《语言模型可以解释语言模型中的神经元》,初步探索大模型智能的可解释性:自动识别哪些部分负责其哪些行为,迈出了使用 AI 进行自动化对齐研究的重要一步。公司还开源了“用GPT-4来解释GPT-2中全部307,200个神经元” 的结果数据集和可视化工具。
抖音发出AIGC平台规范及行业倡议
抖音要求用户在该平台发布的AIGC内容, “进行显著标识”,“虚拟人技术使用者需实名认证”等,禁止发布“侵权内容“或”违背科学常识、弄虚作假、造谣传谣的内容”,并由“发布者对相应后果负责”。抖音向全行业倡议,“使用统一的人工智能生成内容数据标准或元数据标准,便于其他内容平台进行识别。”本周三,中国AIGC管理办法征求意见截止,以内容生成、传播为主的消费互联网平台面临监管压力。谷歌也在I/O科技大会上提出了内容水印和元数据。
百度文心千帆要做大模型生产平台
百度计划将文心千帆打造成大模型生成与分发平台。今年3月刚发布时,文心千帆以文心一言为核心,向平台上的企业客户提供大模型服务。未来,企业可以在文心千帆上基于任何开源或闭源的大模型,开发自己的专属大模型。
周三
微软与甲骨文考虑共享AI算力
甲骨文和微软正在讨论一项不同寻常的协议。双方在为各自的云计算客户服务时,任何一家出现算力不足,都可以租用对方服务器。今年,微软已传出内部AI服务器硬件短缺的消息,被迫采取“配额供给”机制;微软还与AMD合作,资助后者向AI芯片领域扩张,助其开发雅典娜(Athena)芯片。
周四
谷歌闭关炼成PaLM2,努力把AI装进手机
谷歌发布了PaLM2, 旗下搜索、办公、硬件等业务全线拥抱AI 化,与微软竞争。尽管谷歌称基于该新模型的Bard,部分能力已经超越了GPT-4,但早期测评显示它才勉强达到GPT-3.5水平。与OpenAI暂不研发GPT-5不同,谷歌承认研发重心已经转向下一代大模型Gemini。无论是PaLM2还是Gemini,都会拥有不同规模的版本。未来或许“智能手机”会变成“人工智能手机”。
欧盟同意更严格的 AI 监管草案
欧盟议会两个委员会以压倒多数通过了《人工智能法案》相关谈判授权草案,涉及面部识别、生物识别监控和其他AI应用使用的新规则,并将 ChatGPT和类似的生成式AI与高风险系统置于同一级别,要求其遵守额外的透明度要求。6月中旬,欧洲议会全体会议将就该草案表决。欧洲是对人工智能监管立法最快也是最严的主要经济体,谷歌新Bard向全球180多个国家与地区开放,但暂不包括所有欧盟国家。
周五
Token吞吐大扩容,Anthropic是OpenAI最强对手?
大模型的竞争,正在从参数规模转移到Token吞吐量。Anthropic宣布已将大模型Claude的上下文窗口,从9,000个token扩展到100,000个token。此前,OpenAI的GPT-4在上下文窗口大小上达到32,000个token。上下文窗口越大,大模型“记忆力”越好,基于更全面的信息生成内容的应用场景就越多。本周,Anthropic还公布了其宪法AI(ConstitutionalAI),试图将语言模型的内容输出引导到主观上“更安全、更有帮助”的方向。
HuggingFace推出智能代理,调度其他模型
HuggingFace公布了TransformersAgents,它相当于一款用户自己灵活定制的 AutoGPT,能“教会”用户选择的大模型,尝试理解用户给它的提示,调用平台上其他合适模态的大模型,并实时反馈输出结果。单个大模型的创新,可以因此组合起来,为更多细分领域大模型提供更友好的应用环境。